Less code to write, less code to test
I don't think anyone needs to be convinced that writing less code to reach the similar levels of functionality is beneficial.
Fewer lines of code usually results in few tests to run and faster development time.
In this post, I'll explain how much impact the
Deduced Framework had on my code size.
The Observer Pattern
I've always been a fan of the
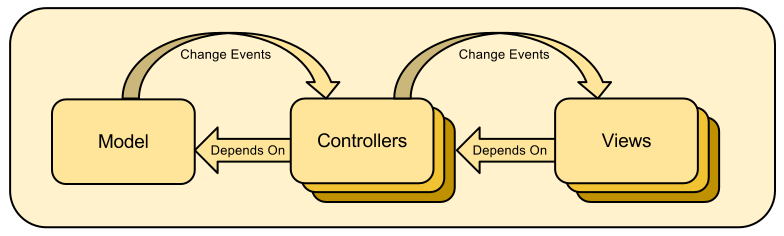
observer pattern. It consists of model objects that notify listeners when they change.
For instance, if a model is displayed in multiple widgets in a user interface, then each widget would listen to the model and update themselves when a change happens.
Besides ensuring that the application remains consistent, it also encourages good software layering practices like
Model View Controller (MVC) where a view could listen to a model without causing the model to depend on the view's implementation.
Simple Use Case : Adding Two Values
Another usage of the observer pattern is to manipulate data based on changing inputs.
For instance, if an application has a model with the following 3 fields:
- Money in my Wallet
- Money in my Bank Account
- Total Money Available
We could then leverage the observer pattern to listen to the wallet and bank account fields.
// extend AbstractObservable to manage listeners and notify them.
// implement Listener to listen to property change events
public interface MyMoney extends AbstractObservable implements Listener{
private int wallet;
private int bank;
private int total;
public MyMoney(){ // constructor
super(); // initialize AbstractObservable
addListener(this); // listen to changes on self
}
public void propertyChanged(ChangeEvent e){
// verify if the field we care about changed
if( e.getField().equals("wallet") ||
e.getField().equals("bank") ) {
// detected a change that has impact on the
// total field, recalculate it
calculateTotal();
}
}
// update the total money available field
public void calculateTotal(){
total = bank + wallet;
}
...
}
Things work well for simple scenarios, but they get complicated when required inputs need to be fetched throughout an object tree.
The code then need to manage listeners across a network of object and react to every change that occurs.
For instance, if the model wants to listen to the money value stored in a list of bank accounts, it would need to:
- Add a listener to the list when it's set.
- Remove the listener on the old list if it gets changed.
- Add a listener to objects added to the list
- Remove listeners on objects removed from the list
Spreadsheets do this without breaking a sweat...
Now compare the same feature implementation on a spreadsheet.
The only formula required here is :
B3=B2+B1
In one line, the formula defines it's inputs, listen to them and executes itself when required.
Compared to the ~7 lines of code written above, it's easy to see how much time and code is saved.
Yet, for all their benefits, spreadsheets have their drawbacks. Every time you need a new instance of a formula, it needs to be copied. It's an obvious violation of the
Don't Repeat Yourself (DRY) principle. If it turns out there is a defect in the formula, the fix needs to be applied everywhere it was copied.
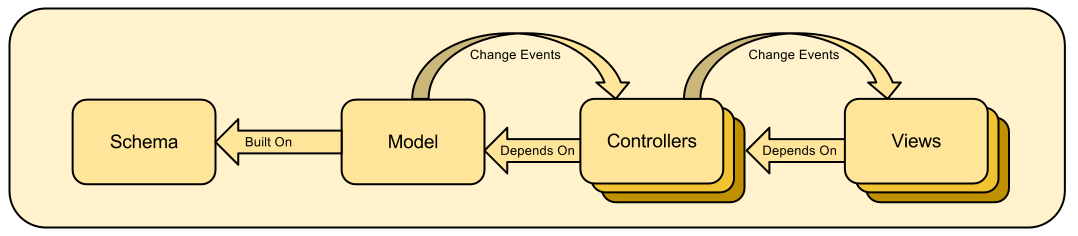
Deduction Rules
The
Deduced Framework attempts to bring the efficiency of spreadsheet formulas into the realm of object oriented development using Deduction Rules.
They consist of the following parts:
- a list of inputs
- a single output
- the java code to execute
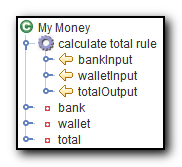
In the example above, a deduction rule could have the following values:
- walletInput : a link to the wallet property
- bankInput : a link to the bank property
- totalOutput : a link to the total property
- Code :
return walletInput + bankInput;
Once defined, the rule will automatically listen to it's inputs, execute the code when they change and update the output value.
We are now back to 1 line of code. On par with spreadsheets. Yet we still have the benefits of object oriented programming where we can create multiple instances of the object without creating multiple copies of the rule definition.
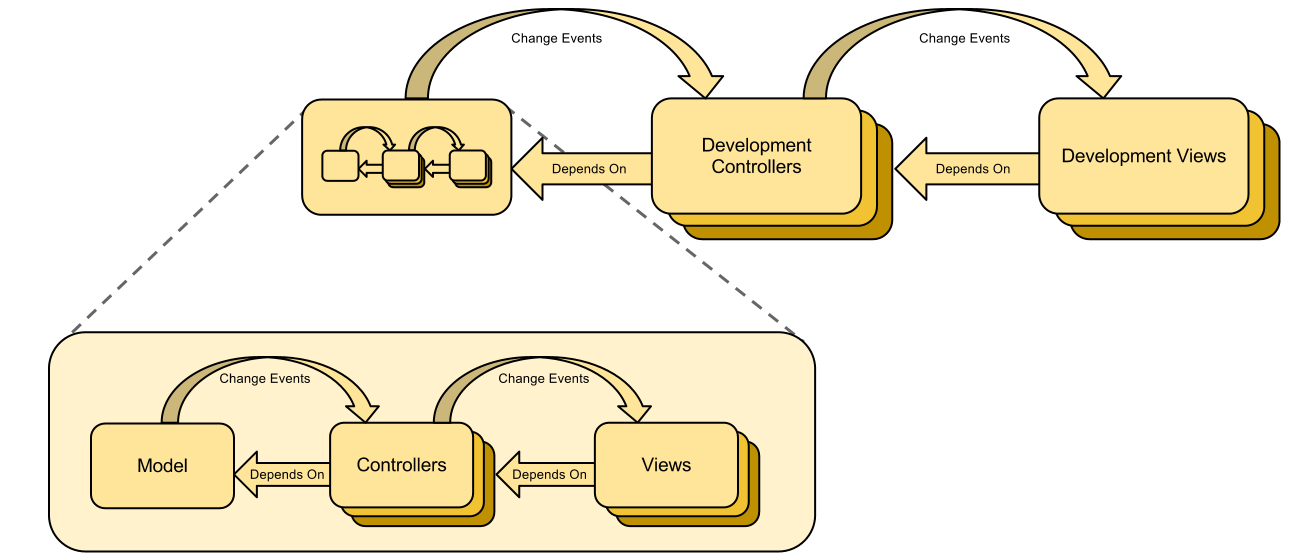
A Bigger Example : Building a Tree
The first time I implemented a visualization tree, I did it with the observer pattern. The code maintained a network of listeners across the model it wanted to represent. It reacted to all possible events that might have an impact on the view. It took about 2000 lines of code to accomplish it's function.
Once deduction rules were introduced, I used them to create a new implementation of the visualization tree. Rules were used to create child tree nodes, set their display text and set their icon. It took only 50 lines of code to accomplish the same function.
That's 40 times less code !
The number of defects I found in the code was proportional to the number of lines. The code is also much easier to learn and extend.
If you're curious to learn more about deduction rules, I encourage you to read on the
Deduced Framework, post a comment below or send me an e-mail at
d-duffATusersDOTsourceforgeDOTnet.


.png)
.png)

.png)