.png) |
| The MCV layers |
Smelly MVC
There are multiple approaches to the MVC design pattern, but few of them ever felt right to me.One of my main gripes with the pattern described on wikipedia is the dependency cycle between the Controller layer and the View layer. Specifically:
- A controller can send commands to its associated view.
- A view must communicate to the controller to activate commands.
Dependency cycles are usually a design smell. While something seems wrong, the answer isn't always obvious.
Another problem arises on the controller layer where the code is usually a mix of commands used to manipulate the model and commands to manipulate the view. I can't help but think that those commands don't belong in the same layer.
The V and C switcharoo
The solution I apply to my designs is to switch the View and Controller layer order, leading to Model Controllers Views or the MCV acronym.The extra 's' aren't there by mistake, but I'll get to it in a moment.
To make it work, I apply a few extra restrictions.
The Controller layer contains no "View" concepts or commands. It is now responsible to modify the model consistently and also to apply security to any changes being done.
The View layers become a bit more thick. They now contain the required logic to build the visual components and interact with their associated control layer.
A new twist comes from the Controller layers that now generates change events consumed by the View layers. This is necessary for model changes that might trigger controller changes. It also adds the benefit that a developer could modify a control layer while the application is running, and the view would keep reacting appropriately.
A RESTful of shmuck
The constraints imposed by REST usually make most developers queasy. How the hell can we make APIs without context ? How can we accomplish every possible change using only PUT, POST and DELETE?
When it comes to monitoring the controller layer, the context restriction hits straight in the teeth. Most controllers need their context to know which user is executing a command. So how do you offer a REST API to monitor a control layer?
The answer : create a control layer instance for each context.
.png) |
| A sample MCV deployment with multiple instances. |
This means a RESTful API can be built to fetch each control layer independently. An administrator or a developer could query the control layer of a specific user to ensure that everything is behaving as expected.
Yo dawg, I heard you like MCV...
...so we put a MCV layer in your MCV layer.If we have a RESTful API on top of our model, our controllers and our views, what stops us from wrapping all of those things together as a single model? Slap development control layers and development view layers on top of it all and use them to monitor, modify and debug all the layers of a running application?
Besides laziness, nothing makes this impossible.
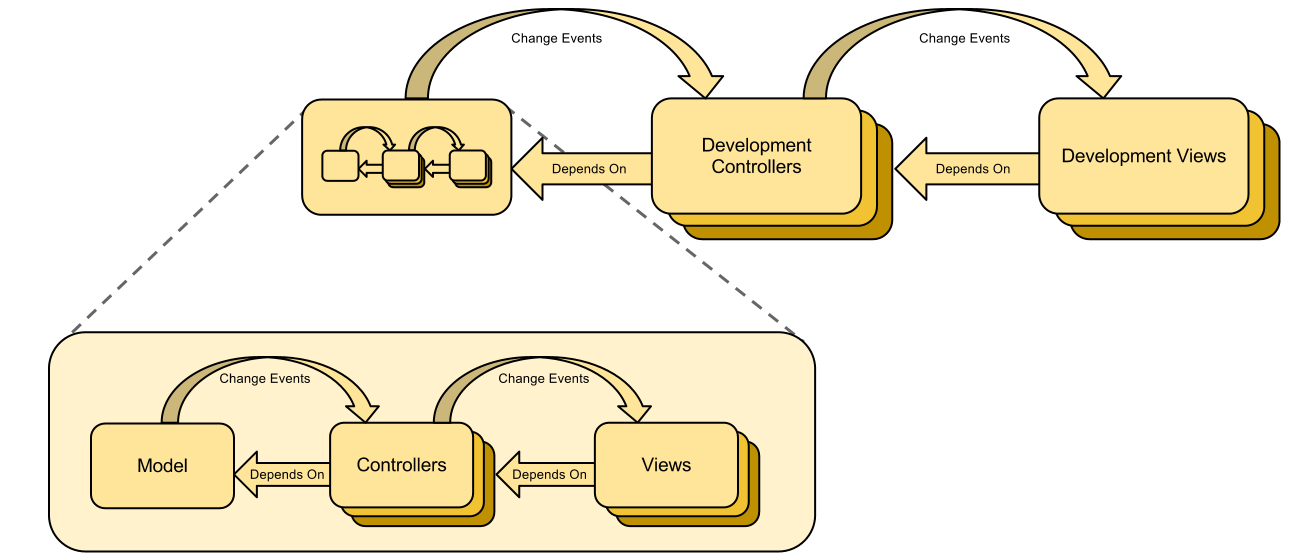 |
| An application MCV wrapped in a development MCV |
I applied this in my pet project : The Deduced Framework. It turned out to be quite convenient; allowing the framework to offer a development environment where everything could be changed while the application is running. Whether it's a view, a controller or a model; everything is laid out in plain view. Developing an entire application without ever stopping it to compile is quite a peasant feeling.
It feels like flirting with the future of development tools, where the idea of stopping an application to compile will be as obsolete as manually managing memory allocation or keeping track of the registries on a CPU.
- Steve McDuff

.png)